Studio
Introducing Graph.Build Studio v3.2
graph.build Studio v3.2 is a major update that expands the platform’s capabilities for designing, transforming, and managing both semantic (RDF) and...
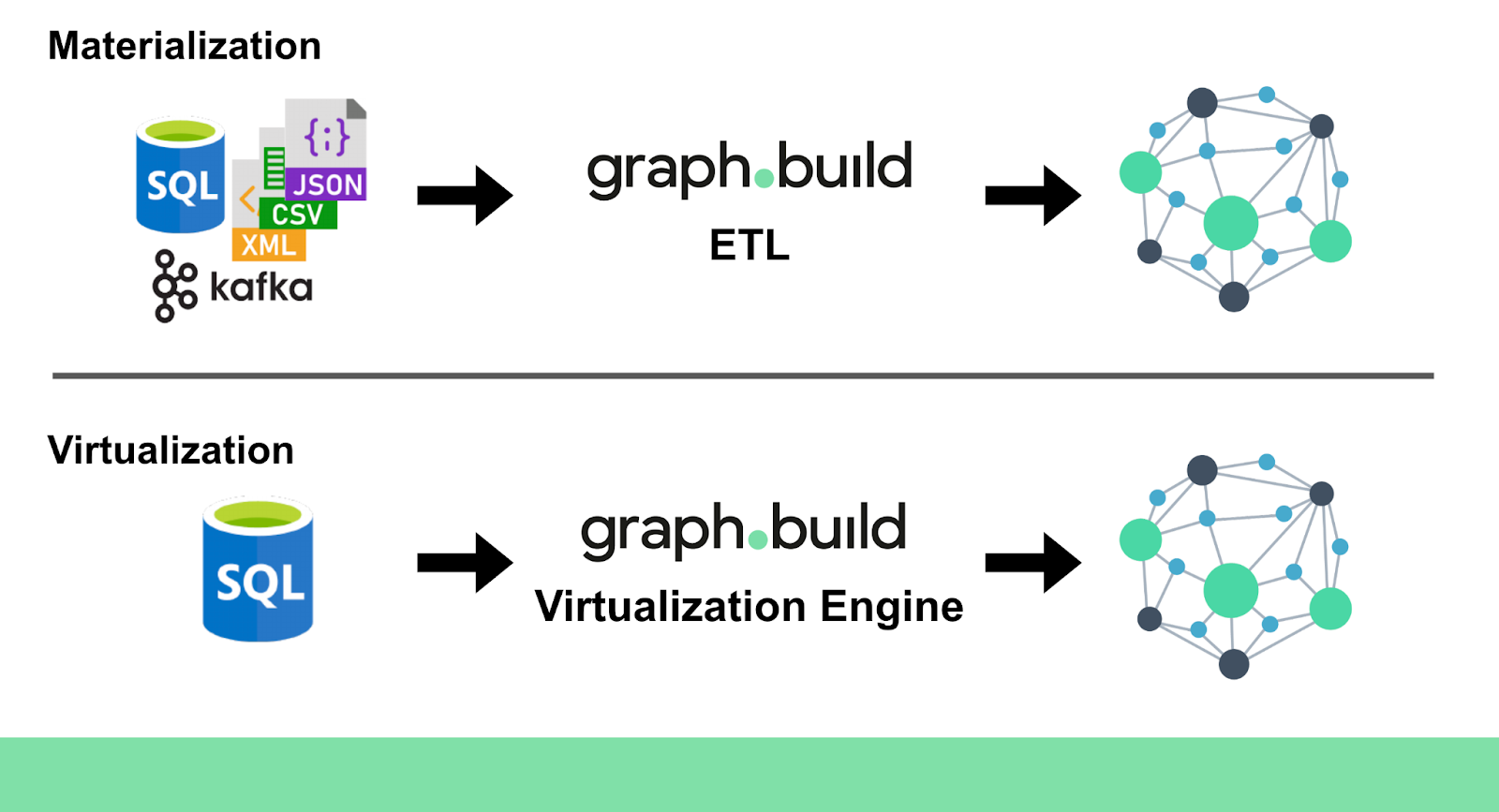
Two approaches dominate the conversation about working with data: graph virtualization and graph materialization. Graph.Build provides the flexibility to use either.
In the world of graph technology, two approaches dominate the conversation when it comes to working with data: graph virtualization and graph materialization. Each method has unique strengths and is suited to different scenarios. At Graph.Build, we provide the flexibility to use either, depending on your needs. In this blog, we’ll explore what these approaches entail, how they differ, and how Graph.Build makes it easy to leverage both.
Graph materialization involves physically creating and storing a graph by importing data from various sources into a graph database. This process typically requires extracting data from relational databases, CSV files, or other data formats, transforming it into a graph structure, and loading it into the desired graph database.
Graph virtualization, on the other hand, allows users to query and interact with graph data without physically replicating it. This approach creates a “virtual” graph by dynamically translating data from its source format into a graph structure at query time.
At Graph.Build, we recognise that different use cases require different approaches. That’s why our platform supports both graph virtualization and materialization, giving you the freedom to choose the method that best suits your needs.
Graph Materialization: Whether you’re working with Semantic RDF or Labelled Property Graphs, use our intuitive ETL pipelines to seamlessly extract, transform, and load data into any graph database of choice. Not only does Graph.Build greatly simplify this process, it also addresses the biggest pain point of materialization - data freshness. By using our Change Data Capture (CDC) functionality or cron scheduler, you can always ensure your data is fully up to date with the source.
Graph Virtualization: Leverage Graph.Build Studio to query and analyse data directly from your relational databases, transforming it into a virtual graph on the fly. This is ideal for scenarios where data needs to remain in its original source or when testing new models without committing to storage. Graph.Build minimises the challenges of virtualization by massively reducing complexity. Build your model, connect to your database, and write SPARQL queries, all with the ability to make iterative changes at any stage.
By supporting and simplifying both approaches, Graph.Build ensures that you can balance performance, efficiency, and flexibility according to your unique requirements.
Whether you’re building persistent graph models through materialization or exploring dynamic, real-time insights with virtualization, Graph.Build has you covered. Our platform is designed to empower you with the tools and flexibility to tackle any graph data challenge.
Ready to get started? Visit our website to learn more, or try out Graph.Build today on AWS Marketplace or Docker Hub. If you’re curious about how Graph.Build can transform your data strategy, reach out to us for a demo.
Follow us on LinkedIn to stay updated with the latest innovations in graph technology!
Russell Waterson is a Lead Software Engineer at graph.build, specialising in full-stack development with a focus on Knowledge Graphs, Linked Data, and the Semantic Web. With extensive experience in frontend, backend, and cloud technologies, Russell plays a key role in designing and implementing graph-based solutions that help organisations manage and transform their data more effectively.
graph.build Studio v3.2 is a major update that expands the platform’s capabilities for designing, transforming, and managing both semantic (RDF) and...
Graph.Build have released version 2.1 of the Graph.Build Studio - featuring RDF Data Synthesization, Enhanced Features for LPG, and Model Import /...
This is a step-by-step example of how to create a knowledge graph model, or any other graph model, using the Graph.Build no-code Studio solution.